|
首页
前一页
后一页
末页 [144] [145] [146] [147] [148] |
本留言簿共有493条记录, 现在时间2025-12-15 18:34:49,计算机地址:192.168.9.44
日期查询: |
现在是第29页 一共有99页 |
| Books库中表及结构信息 | 环境:一键安装 库表:Mysql.sql xx3.sql xx4.sql 页面:Myphp.php |
| 序号 | 留言内容 |
|---|---|
|
D:2011-11-23 T:18:00:00 IP:192.168.8.40 作者: 张顺海 | 2011.11.24 星期四 教学内容:数据表格内容的导出 教学目的:把数据表中的筛选内容导出成其他格式的文件 教学重点:导出成excel文件及文本文件 教学难点:文件格式
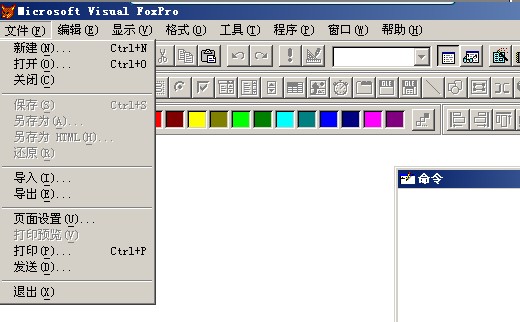
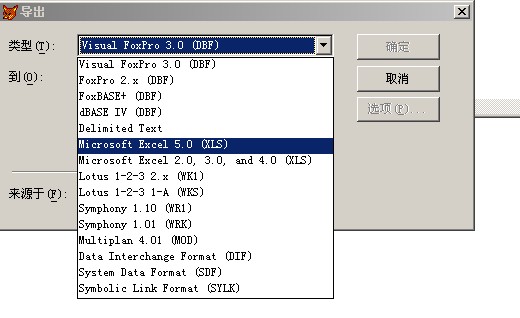
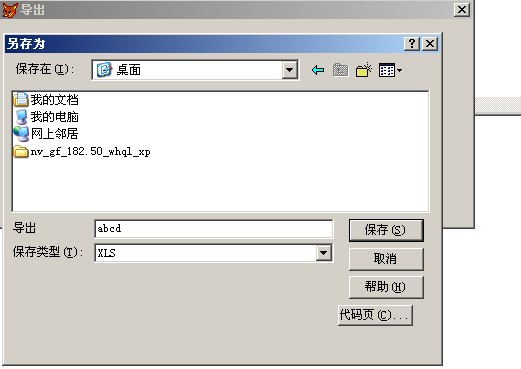
一、上节回顾 上节我们学习了“into table”短语,它的意思是让我们筛选出来的数据,把它保存到一张新的表格里,新形成的表格和我们学习使用的tushu.dbf一样可以做为数据源使用。 作业中的第二题: 将图书表格中的,单价在15至55之间(含15和55)的所有图书,保存到test1117_3.dbf中,答案是: sele * from tushu where 单价 between 15 and 55 into table test1117_3 作业中出现的主要问题: 1.在使用条件短语的时候,部分同学丢失了where关键词。 2.15至55元之间,应该使用 单价 between 15 and 55,有部分同学使用的是 单价 in (15,55)。 3.有部分同学没有使用 into table test1117_3,只是完成了筛选动作,没有完成结果的保存动作。 4.有部分同学把文件名test1117_3中的下划线,写成了减号,即 test1117-3 二、新授 1.文件的导出 VFP使用的表格文件的扩展文件名为 .dbf,是一种特殊格式的文件,一般情况下,用VFP软件打开使用,其他的文件操作起来非常的不方便,有的根本打不开,所以需要使用VFP的【导出功能】,把它保存为其他软件如“excel”或“word”或“记事本”等程序使用的格式。 2.excel格式的导出步骤 执行相应的筛选指令,选出需要的数据,一般使用的命令为:sele * from tushu where .....的格式。 点菜单【文件】-【导出】,会出现【文件类型】(Microsoft Excel )-【保存位置】(桌面)-【确定】-【产生相应的文件】
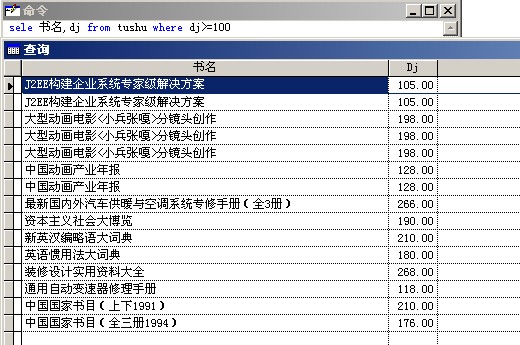
3.文本文件的导出: 使用的短语为:to file 如:sele 书名,dj from tushu where dj>=100 to file abcd.txt 这样就把结果保存到了文本文件“abcd.txt”中了。 三、练习 请大家在【桌面】上建立“上次作业题目中的结果”的文本文件“test1123_1.txt”,请大家想想,什么是“文本”文件,它的扩展名为“.txt”,它通常用什么程序打开? 四、作业 1.将‘大众文艺’出版社出版的图书“书名”、“dj”、“套数”内容保存到“excel”格式的文件test1123_2.xls中。 2.将dj是(15,20,25,27,32)的图书的“书名”、“dj”、“版别”等三项内容保存到“文本”格式的文件test1123_3.txt中。 |
|
D:2011-11-15 T:12:42:00 IP:192.168.8.40 作者: 张顺海 | 2011.11.17(星期四)授课内容 1.教学内容:into table短语 2.教学目的:掌握查询得到的结果,保存到一个新的表格里 3.教学重点:into table <表格名>的使用 4.教学难点:新表格的存储位置
一、上节课的作业情况:http://192.168.8.40/ch01/zyd.htm 二、作业情况汇总
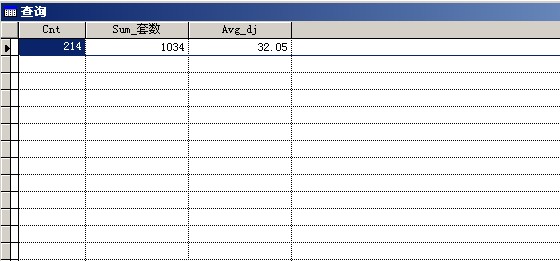
三、内容回顾 1.聚合函数: count() 返回对符合条件的统计个数 sum() 返回符合条件的记录中指定列数据求和 avg() 返回符合条件的记录中指定列数据的平均值 max() 返回符合条件的记录中指定列数据的最大值 min() 返回符合条件的记录中指定列数据的最小值 2.分组统计:group by 短语 题目1中使用的对符合条件的记录统计成一个结果。 例:sele count(*),sum(套数),avg(dj) from tushu where 版别 like "%大众文艺%" 解:对tushu.dbf中的‘大众文艺’出版社的图书进行相应的统计,分析是‘大众文艺’的记录个数(count(*)),‘大众文艺’出版社的套数之和(sum(套数)),‘大众文艺’出版社所有图书的平均单价(avg(dj))来完成的,结果只有一行。
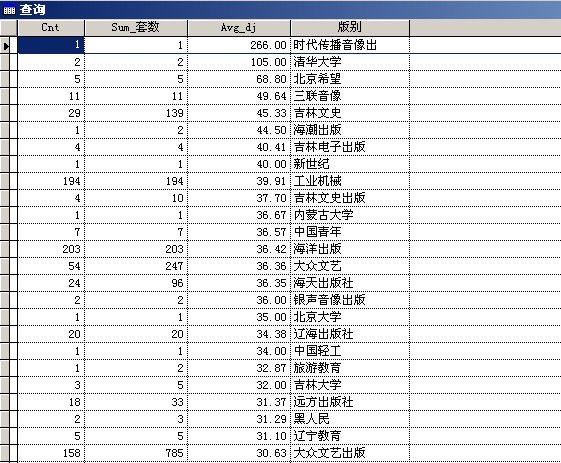
图1 如果使用了group by 选项就会按照它指定的项目,如: group by 版别:就会按照版别分类,每一类就会组合到一起,形成单独的统计。 如:sele count(*),sum(套数),avg(dj),版别 from tushu group by 版别
图2 四、新授 问题提出:得到的结果(上边图1和图2),可以保存到一张的表格里,做为其他用途。 1.短语: into table <表格名> 2.目的:就是把查询的结果保存到新的表格中,新的文件事由 <表格名>指定,默认的扩展文件名为.dbf,保存位置就是当前文件夹,也就是启动VFP6的文件夹。当然可以指定文件保存的位置。 如: .... into table d:\abc\xy10 表格保存到了d盘,abc子文件夹中,文件名为 xy10.dbf 3.例:将图2的内容保存到当前文件夹里,文件名为 test1117_1.dbf (共有71条记录) sele count(*),sum(套数),avg(dj),版别 from tushu group by 版别 orde by 3 desc into table test1117_1 五、练习 将书名中含有‘王’字的所有图书信息筛选出来,保存到表格test1117_2.dbf中。 六、作业 1.我们学习了哪个短语,有什么用? 2.将图书表格中的,单价在15至55之间(含15和55)的所有图书,保存到test1117_3.dbf中。 |
|
D:2011-11-15 T:10:58:00 IP:192.168.8.40 作者: 张顺海 | 今天是2011年11月15日,星期二。AMD公司发布了多款多核CPU产品。
|
|
D:2011-11-9 T:9:43:00 IP:192.168.8.40 作者: 张顺海 | 2011.11.10 授课内容 教学内容:查询过程的聚合函数、分组短语的利用 教学目的:掌握统计函数,智能统计结果 教学重点:max()、min()、总数() 教学难点:group by
一、考试分析 平均成绩:V52是17.85分,V55是17.33,满分20分。 错误最多的: 选择题第10题:将书名中含有‘王’字的图书信息筛选出来的条件:应该选择D选项是“以上都不对”,因为应该利用like和通配符配合,如:书名 like "%王%" 操作题第1题:将图书信息中含有‘中国’的所有信息找出来,多数人在条件中丢落了项目名,应该是 sele * from tushu where 书名 like '%中国%',多数人丢落了‘书名’这个重要的项目。 二、新授 1.最大值、最小值、求和的聚合函数应用: 最大值:max() 最小值:min() 求和:sum() 2.实例: (1)求‘大众文艺’出版社出版的图书的最高单价和最低单价; sele * from tushu where 版别 like "%大众文艺%" '所有大众文艺出版社出版的图书信息 sele count(*) from tushu where 版别 like "%大众文艺%" '统计上述图书的记录条数 sele max(单价),min(单价) from tushu where 版别 like "%大众文艺%" '查询大众文艺出版社出版的最高单价、最低单价 sele sum(套数),版别 from tushu where 版别 like "%大众文艺%" '统计大众文艺出版社出版的总套数 (2)对不同的出版社分析统计最高单价、最低单价、总套数 分组:就是把记录按指定的项目(本题就是按版别)分类,同一类的统计中最大值、最小值、求和。 实现:sele count(*),版别 from tushu group by 版别 order by 版别 desc '按版别分类,同一个出版社分别计数(记录的条数) 同理:sele max(单价),min(单价),sum(套数),count(*),版别 from tushu group by 版别 order by 版别 desc 三、练习 1.统计不同类别图书中的最高单价,最低单价、总套数、平均单价 sele 类别,coun(*) as 记录数,max(dj) as 最高单价,min(dj) as 最低单价,sum(套数) as 总套数,avg(dj) as 平均单价 from tushu group by 类别 2.按出版社统计出每个出版社出版图书的总价格 sele 版别,sum(dj*总册数) as 总价格 from tushu group by 版别 orde by 版别 desc 四、作业 1.今天我们学习了三个聚合函数一个短语,分别是什么? 2.按图书类别统计出不同类别的总套数、平均单套册数、平均单价? |
|
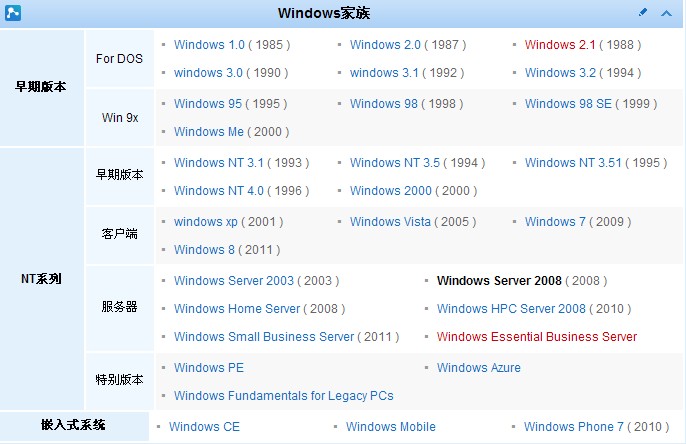
D:2011-11-8 T:10:30:00 IP:192.168.8.40 作者: 张顺海 | windows家族一览表
|